Skill Design
for LLM Agents
Writing good skills that actually work
Minko Gechev
Agentic systems
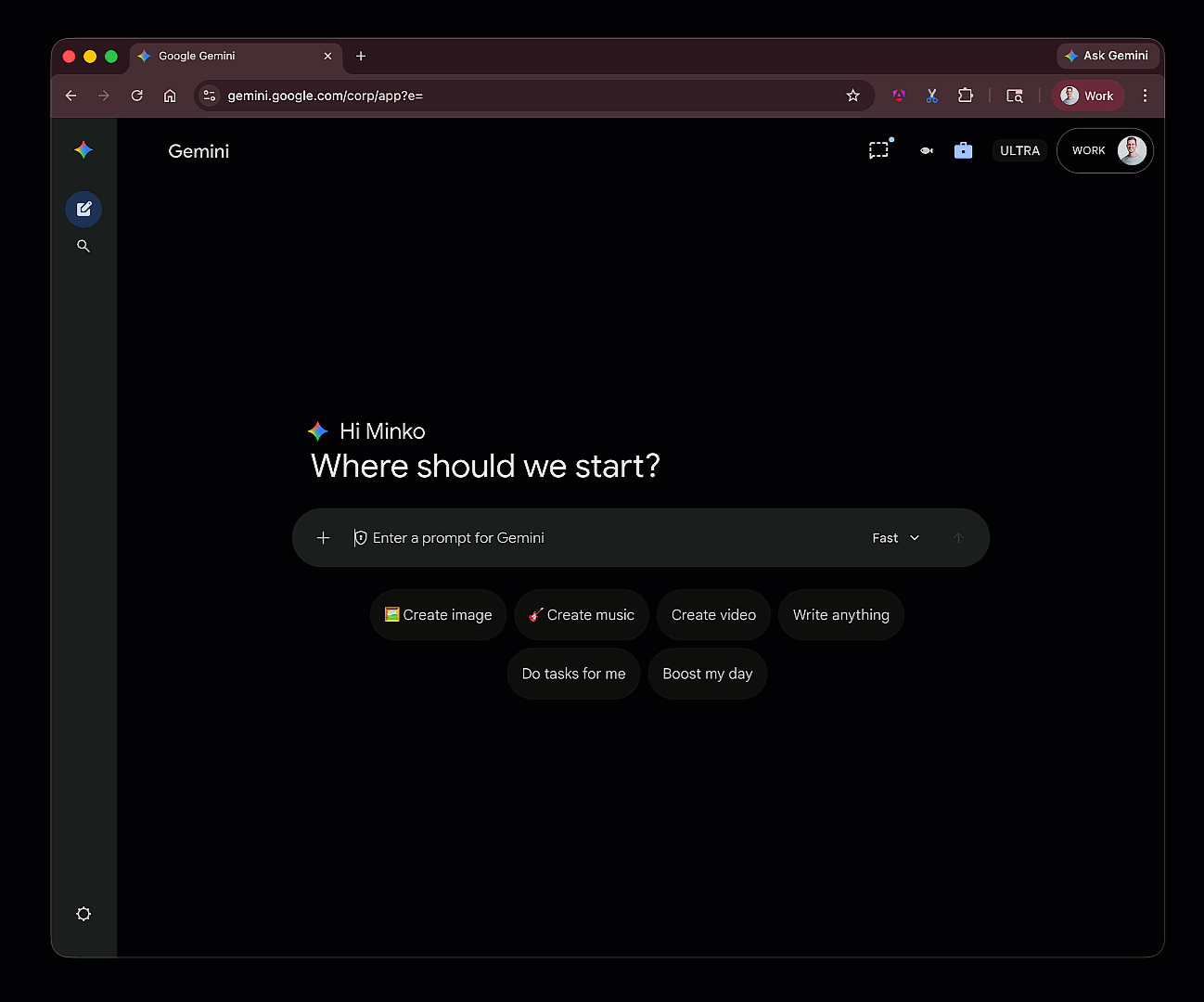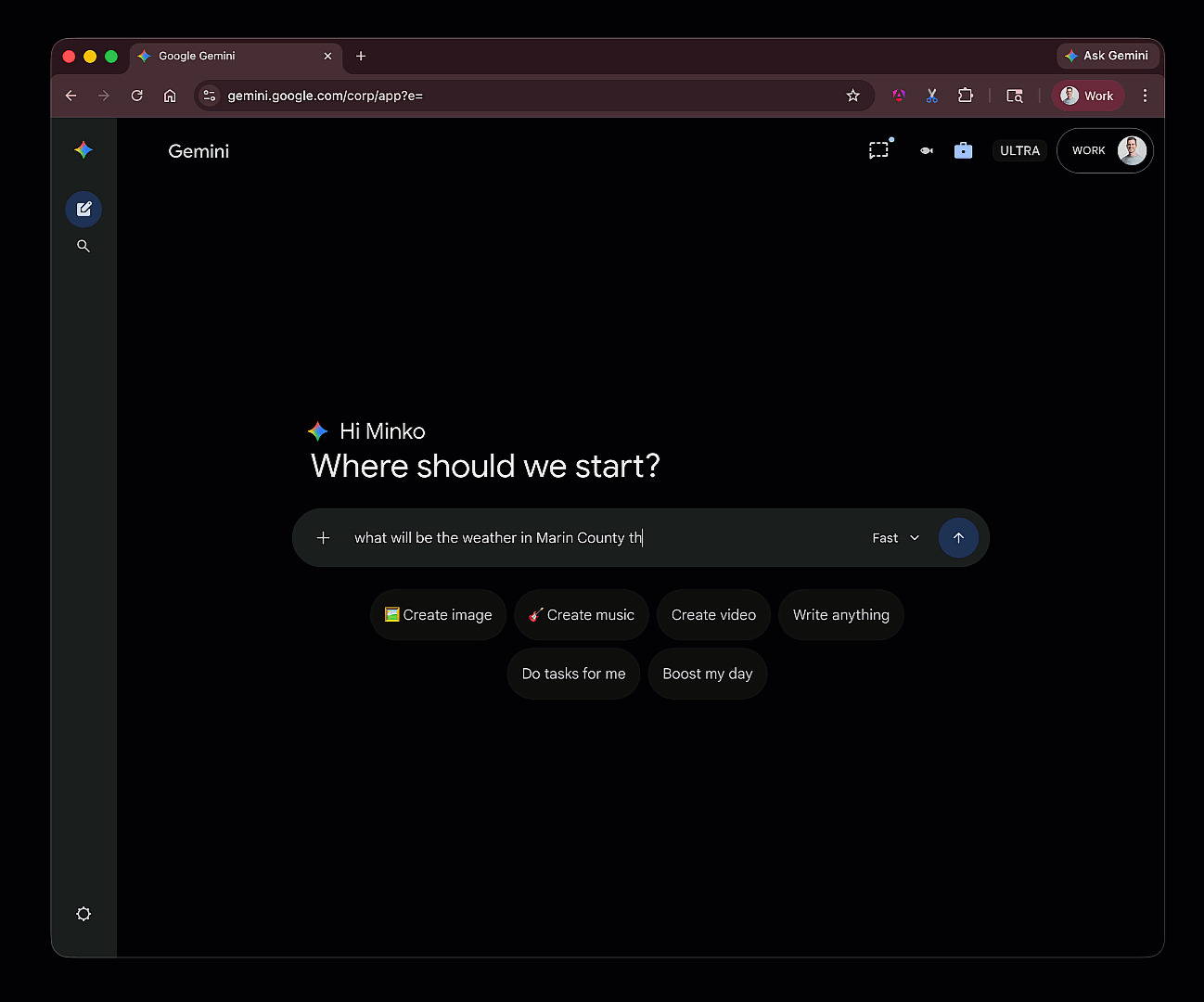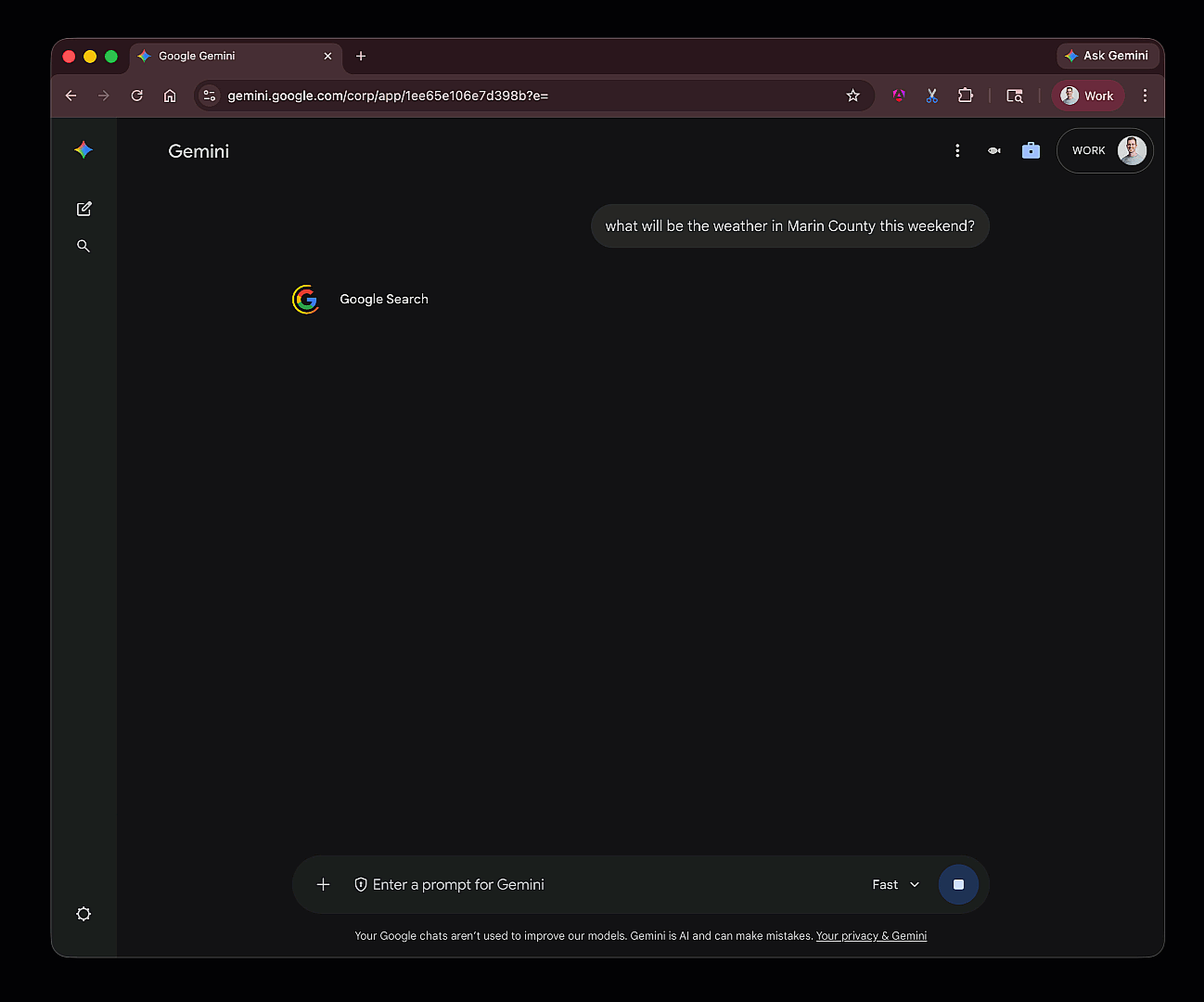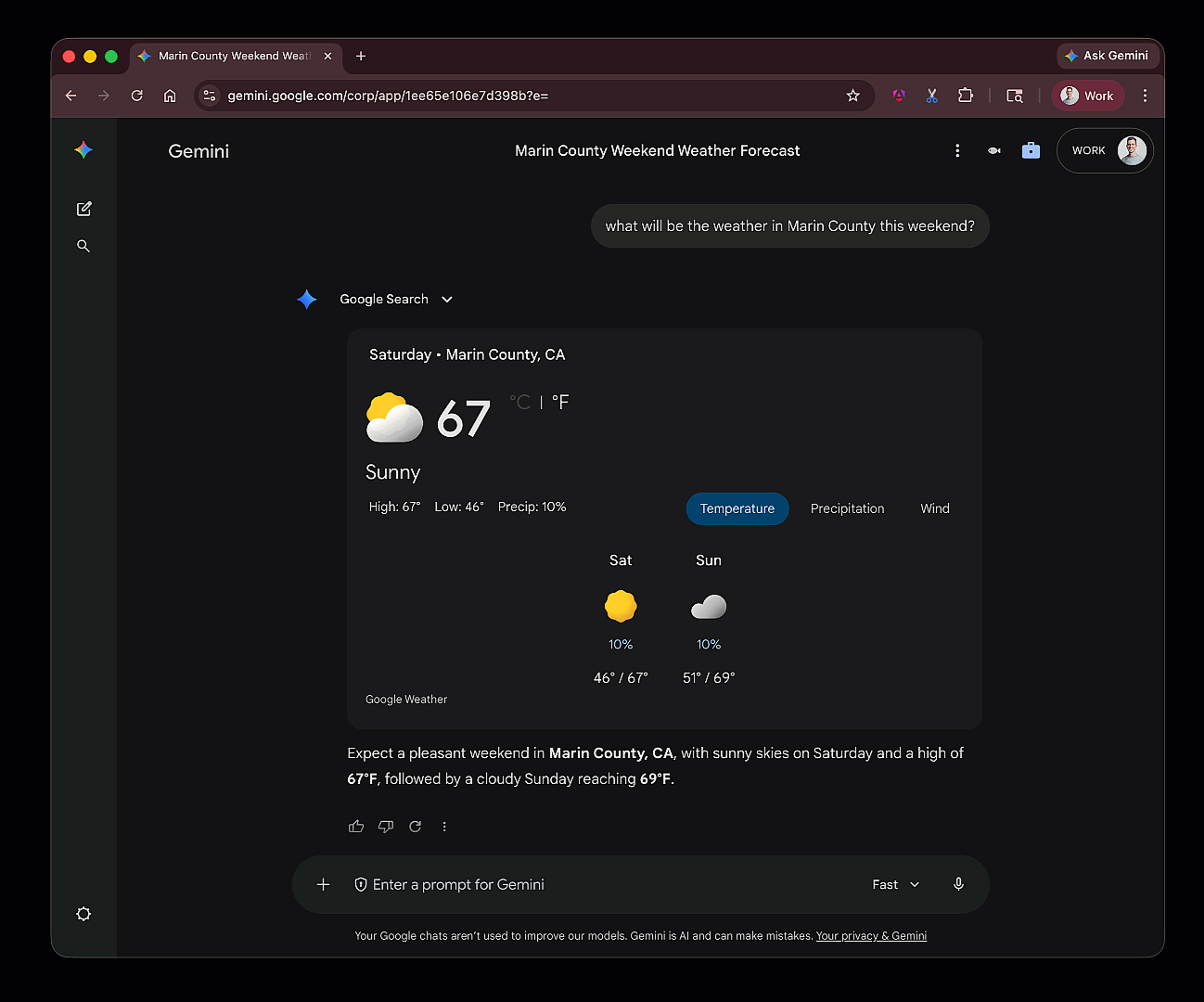
How agents work?
How agents work?Model Context Protocol
Common agent architectures
- ReAct (Reason + Act) - agent loops between thought generation, action, and observation until the goal is met.
- Plan-and-Execute - agent creates a full, multi-step plan upfront and adjusts it while executing each task.
- Reflexion (Self-Correction) - agent evaluates its performance post-task, using internal feedback to improve future attempts.
- State Machine-Based Agents - agent's reasoning and tool use are strictly confined by a predefined flowchart, ensuring reliable execution.
- Hybrid - popular agents often include a mixture of the architectures from above
Simplified ReAct loop
user_prompt := get_user_prompt() context := user_prompt + system_instructions while true { tools := get_available_tools() response := ask_llm_what_to_do(tools, context) if response.done { break } if response.tool_calls { result := call_tools(response.tool_calls) } context := context + result }
Simplified ReAct loop
user_prompt := get_user_prompt() context := user_prompt + system_instructions while true { tools := get_available_tools() response := ask_llm_what_to_do(tools, context) if response.done { break } if response.tool_calls { result := call_tools(response.tool_calls) } context := context + result }
Simplified ReAct loop
user_prompt := get_user_prompt() context := user_prompt + system_instructions while true { tools := get_available_tools() response := ask_llm_what_to_do(tools, context) if response.done { break } if response.tool_calls { result := call_tools(response.tool_calls) } context := context + result }
Simplified ReAct loop
user_prompt := get_user_prompt() context := user_prompt + system_instructions while true { tools := get_available_tools() response := ask_llm_what_to_do(tools, context) if response.done { break } if response.tool_calls { result := call_tools(response.tool_calls) } context := context + result }
Simplified ReAct loop
user_prompt := get_user_prompt() context := user_prompt + system_instructions while true { tools := get_available_tools() response := ask_llm_what_to_do(tools, context) if response.done { break } if response.tool_calls { result := call_tools(response.tool_calls) } context := context + result }
Simplified ReAct loop
user_prompt := get_user_prompt() context := user_prompt + system_instructions while true { tools := get_available_tools() response := ask_llm_what_to_do(tools, context) if response.done { break } if response.tool_calls { result := call_tools(response.tool_calls) } context := context + result }
Simplified ReAct loop
user_prompt := get_user_prompt() context := user_prompt + system_instructions while true { tools := get_available_tools() response := ask_llm_what_to_do(tools, context) if response.done { break } if response.tool_calls { result := call_tools(response.tool_calls) } context := context + result }
Simplified ReAct loop
user_prompt := get_user_prompt() context := user_prompt + system_instructions while true { tools := get_available_tools() response := ask_llm_what_to_do(tools, context) if response.done { break } if response.tool_calls { result := call_tools(response.tool_calls) } context := context + result }
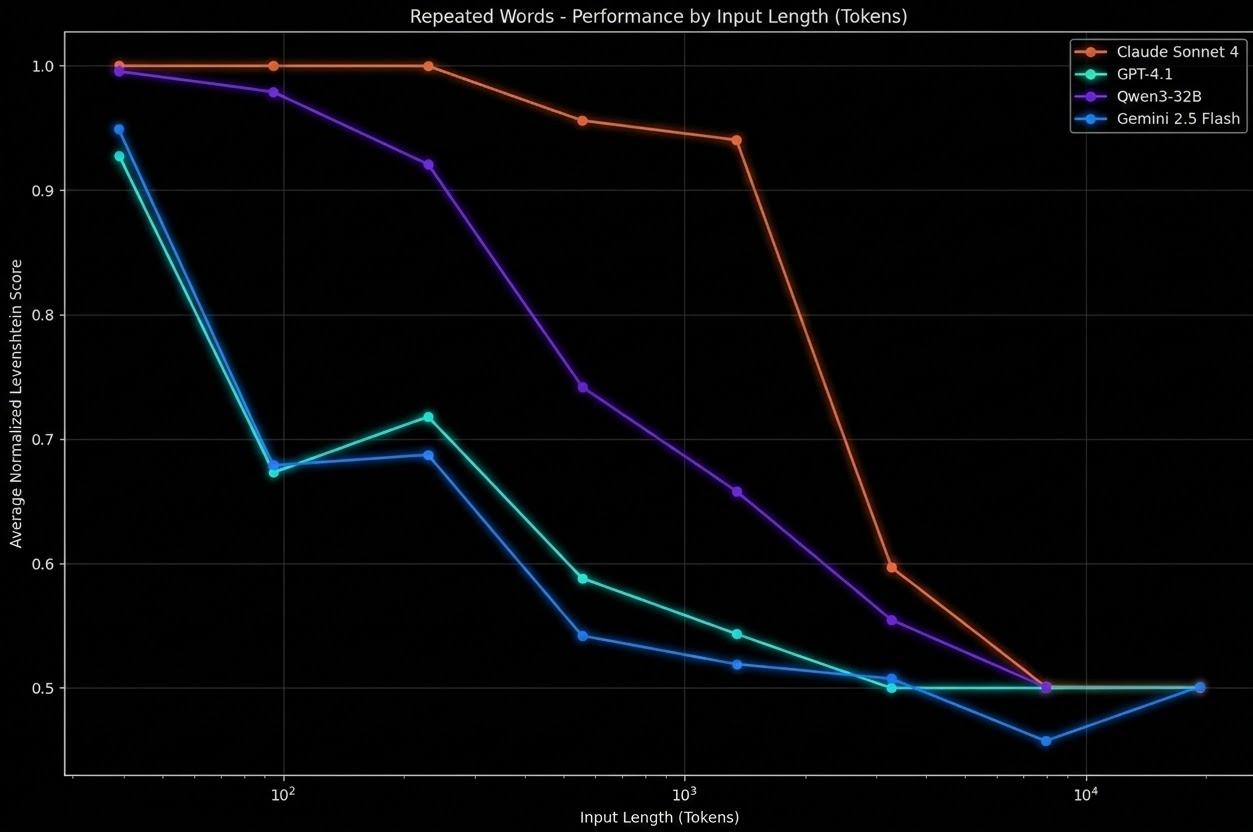
Making agents more powerfulnon-exhaustive list
Making agents more powerfulnon-exhaustive list
Making agents more powerfulnon-exhaustive list
Two ways of making agents more powerful
…while avoiding context rot
CLI vs MCP
- Context preservation - no context bloat through JSON schemas
- Auth and permissions - leverage existing user credentials and SSO
- Zero infra overhead - no local background child processes
- Human-in-the-loop debugging - easy to debug since they run in user context and are simple binaries
Agent skills
Specific procedural instructions for the agent how to do a task
Skill directory structure
├── SKILL.md # Instructions & YAML metadata
├── scripts/ # Executable programs / logic
│ └── helper.py
├── references/ # Heavy reference documentation
│ └── examples.md
└── assets/ # Templates or static assets
└── config.json
The core entry point containing the metadata and step-by-step instructions written in markdown.
Programs (Python, Bash, Node.js) triggered by the agent to run deterministic/repetitive operations.
Static context loaded dynamically on-demand, keeping the main skill file lightweight (< 500 lines).
Sample SKILL.md file
--- name: deploy-firebase description: Deploys project assets to Firebase --- # Deploy Procedure ## Step 1: Pre-flight checks 1. Run `npm run build` to compile assets. 2. Read `references/checklist.md` to confirm. ## Step 2: Run Deployment 1. Run `firebase deploy` in the terminal.
Declares the skill's name and description. Crucial for matching: the agent matches this description against user queries.
Steps written in standard Markdown. Tells the agent exactly what to check, read, or run to complete the task.
CLAUDE.md vs. Skills
- Scope: Repository-wide rules & coding guidelines.
- Resolution: Static file loaded fully into context at start.
- Capability: Passive instructions (style guides, build commands).
- Portability: Bound to a single repository.
- Scope: Task-specific or workflow-specific logic.
- Resolution: Selected dynamically using YAML metadata.
- Capability: Active execution (scripts, references, custom tools).
- Portability: Portable, reusable modules across projects.
Skills are unnecessary if the agent already possesses the capability
How do skills work?
skills := get_available_skills() response := ask_llm_for_skills(skills, context) if response.skills { result := read_skills(response.skills) } context := context + result
How do skills work?
skills := get_available_skills() response := ask_llm_for_skills(skills, context) if response.skills { result := read_skills(response.skills) } context := context + result
Five Best Practices for Agent Skills
01. Procedural Instructions
"To run tests, first check if npm is installed. You can look for package.json. If yarn is used, run yarn. If npm is used, run npm. It is generally better to run npm ci to make sure dependencies match."
2. If yarn.lock is present, execute:
yarn install --frozen-lockfile
3. If only package.json is present, execute:
npm ci
4. Execute: npm test
02. Frontmatter Optimization
Keep registries small — too many skills degrade selection accuracy. Large registries need retrieval filtering before the LLM sees them.
Registry Size & Accuracy
03. Progressive Disclosure
├── SKILL.md # Plan under 500 lines
├── scripts/ # Execution scripts
│ └── run-karma.sh
├── references/ # Static configuration details
│ └── test-configs.md
└── assets/ # Structured templates
Increases latency and execution cost. High risk of key instruction dilution inside the LLM context window.
Maintains rapid response times and accuracy. Dynamic reference loading is deferred until explicitly needed.
04. Repetitive Task Scripting
To run the migration:
1. Search: grep -rl "Karma" ./src
2. Replace: sed -i 's/Karma/Jest/g' ./config
3. Set env: export TEST_ENV=prod
4. Verify: node ./scripts/build-check.js
Listing manual commands inside the skill file increases parser mistakes and points of failure.
To run the migration, execute the wrapper script:
./scripts/migrate-tests.sh --env=prod
Wrapping the multi-step sequence in a modular script guarantees reliable and atomic execution.
05. Skill Composition
- Use high-level entry points to conditionally trigger targeted sub-skills.
- Allows clean routing paths instead of consolidating all logic in one document.
- Keeps individual skills focused, modular, and easy to maintain.
Skills versus scripts
Testing skills
- Ensures a skill is useful
- Prevent regression
- Removal of unused skills
- Hill-climbing
Agentic testing pyramid
compositions (e2e tests)
(composition of
skills & CLIs) (integration tests)
Agentic testing pyramid
compositions (e2e tests)
(composition of
skills & CLIs) (integration tests)
Skill evals
- Identify goals - based on your skills identify goals for your agent
- Create tasks - provide "assignments" with context to achieve the goals; include negative cases where the skill should not trigger
- Run trials - run 5-30 executions of the workflow
- Grade
- Script grader - code evaluates the "state of the world"
- LLM grader - model grades the "trajectory"
- Human grader - looks at the output (we'll ignore this for now)
Evals terminology
skillgrade
"Unit tests" for your agent skills
How to create evals?
- Provide API key as env var
- Skillgrade will autogen evals
- Run and report results
Takeaways
Prefer CLIs over MCP
Extend agent toolsets securely with zero runtime daemon overhead.
Teach the Unknown Only
Build skills for new workflows, avoiding redundant instruction bloat.
Apply the Five Practices
Structure skills with deterministic steps, lean core files, and scripts.
Establish Automated Evals
Measure agent performance using custom script and LLM graders.
Iterate via Hill Climbing
Continuously run trials to systematically drive up pass rates.
Takeaways
Prefer CLIs over MCP
Extend agent toolsets securely with zero runtime daemon overhead.
Teach the Unknown Only
Build skills for new workflows, avoiding redundant instruction bloat.
Apply the Five Practices
Structure skills with deterministic steps, lean core files, and scripts.
Establish Automated Evals
Measure agent performance using custom script and LLM graders.
Iterate via Hill Climbing
Continuously run trials to systematically drive up pass rates.
Takeaways
Prefer CLIs over MCP
Extend agent toolsets securely with zero runtime daemon overhead.
Teach the Unknown Only
Build skills for new workflows, avoiding redundant instruction bloat.
Apply the Five Practices
Structure skills with deterministic steps, lean core files, and scripts.
Establish Automated Evals
Measure agent performance using custom script and LLM graders.
Iterate via Hill Climbing
Continuously run trials to systematically drive up pass rates.
Takeaways
Prefer CLIs over MCP
Extend agent toolsets securely with zero runtime daemon overhead.
Teach the Unknown Only
Build skills for new workflows, avoiding redundant instruction bloat.
Apply the Five Practices
Structure skills with deterministic steps, lean core files, and scripts.
Establish Automated Evals
Measure agent performance using custom script and LLM graders.
Iterate via Hill Climbing
Continuously run trials to systematically drive up pass rates.
Takeaways
Prefer CLIs over MCP
Extend agent toolsets securely with zero runtime daemon overhead.
Teach the Unknown Only
Build skills for new workflows, avoiding redundant instruction bloat.
Apply the Five Practices
Structure skills with deterministic steps, lean core files, and scripts.
Establish Automated Evals
Measure agent performance using custom script and LLM graders.
Iterate via Hill Climbing
Continuously run trials to systematically drive up pass rates.
Takeaways
Prefer CLIs over MCP
Extend agent toolsets securely with zero runtime daemon overhead.
Teach the Unknown Only
Build skills for new workflows, avoiding redundant instruction bloat.
Apply the Five Practices
Structure skills with deterministic steps, lean core files, and scripts.
Establish Automated Evals
Measure agent performance using custom script and LLM graders.
Iterate via Hill Climbing
Continuously run trials to systematically drive up pass rates.